The counterfeit coin puzzle

The logical puzzle goes something like this:
Given a two-pan fair balance and N identically looking coins out of which only one coin may be defective. How can we trace which coin, if any, is the odd one by weighing it in minimum number of trials in the worst case?
In other words, we have a two-pan balance scale and some amount of coins in which zero, one or many are fake, which is determined by its weight being smaller than the rest. In this post, we are only going to consider the case where we know for certain that we have exactly one counterfeit coin in our stack.
When I originally read this puzzle, only 9 coins were considered. I first started thinking about how to solve the puzzle itself, but quickly ran into thinking about generalizing it into N coins, and algorithms for solving it. Please give the puzzle a thought yourself before continuing on with this blog post.
Non-optimal system 1 solution
In his book Thinking, Fast and Slow 1, Daniel Kahneman presents two different systems or modes that drives the way our brains work. System 1 is fast, intuitive and emotional while the slower system 2 is more systematic and logical. When we are faced with challenges, be it at work, in relationships, physical or mental, our brains initially tend towards system 1 thinking unless we give the it proper good thought. Like with these challenges, this puzzle might lead you to a suboptimal solution unless you roll up your sleeves. One such solution is splitting the stack of coins into two groups that we weigh against each other. For 9 coins, we'd therefore be dividing them into two groups of four and weigh them against each other. The lighter of the two are then divided into two new groups and so on until we are left with comparing two coins. This strategy yields a worst case of 3 trials for 9 initial coins. Is there a way to reduce the number of trials even more?
The key insight
Yes there is! The key insight into finding the optimal solution to the puzzle is to consider that there are actually three potential outcomes to a trial.
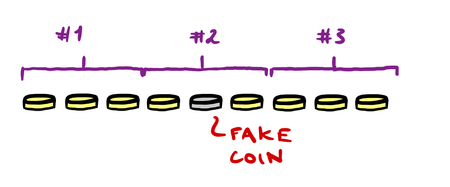
Let me explain this in more detail: When weighing two groups, which we will name group A and group B, the aim is to discard all the coins which we know does not contain the fake coin. If we divide our coins in to two equal groups and weigh them against each other, we might for example learn that group A contains a lighter coin and therefore discard group B, halving our set of coins. So where does three come in? The three different outcomes of a trial is described in the table below in addition to the strategy for what do about it:
| Outcome | Strategy |
|---|---|
| Group A is lighter | Keep only group A |
| Group B is lighter | Keep only group B |
| They weigh the same | Discard both groups |
The third option, that is, the two groups weigh the same, is only possible if you intentionally set aside some coins for a third group (group C) outside the trial.
Finding the worst case lowest number of trials necessary is a matter of excluding as many coins as possible on a single trial. We achieve this by evenly dividing our coins in such a way that the information about what coins to discard after a trial can be applied to as many coins as possible. Leveraging the fact that there are three outcomes means we can essentially discard ~66% of the set after each trial if we divide our set into three as opposed to only ~50% if we divided the set into two.
The algorithm
The general algorithm is pretty straight forward after understanding how to best divide our set. We can apply the divide-and-conquer paradigm by first solving the first couple of cases and though not shown in this post, follow up with a proof by induction showing that all numbers of initial coins lead to the base cases. First of all, the algorithm for finding the one fake coin in a set of N coins by using a two-pan balance can be described stepwise as:
- Divide the set of N coins into three equal groups. If the number of coins is not divisible by three, divide them as equally as possible, leaving the last group smaller than the rest.
- Weigh the two equal groups against each other.
- Discard the two groups that do not contain the counterfeit coin as described in the table above.
- Repeat procedure on the remaining group until left with a single coin (the counterfeit)
In code
In python code, we will represent the coins as an array of 1's where the counterfeit coin is represented as a 0. We will start off with a small function that generates this array of coins in a random fashion:
import random
def getInitialSetOfCoins(numCoins = 9):
seed = random.randint(0, numCoins - 1)
# List of normal coins (1) with a light coin (0) placed randomly
return [1 if i != seed else 0 for i in range(numCoins)]
We also need a function that takes in two arrays of such coins and returns 0 if the first array is the lighter of the two, 1 if the last array is the lighter of two or 2 if they wheigh the same:
# Determines the lightest of two lists of coins
def getLowestWeight(firstCoins, secondCoins):
firstWeight = sum(firstCoins)
secondWeight = sum(secondCoins)
return 0 if firstWeight < secondWeight else (1 if firstWeight > secondWeight else 2)
That's all we need. The procedure can then be written
import math
def procedure(coinArray):
index = 0
count = 0
div = math.ceil(len(coinArray) / 3)
j = getLowestWeight(coinArray[:div], coinArray[div:2 * div])
count += 1
if div == 1:
index += j
else:
k, c = procedure(coinArray[j * div:(j + 1) * div])
count += c
index += k + div * j
return index, count
which we can set up and call like this:
coins = getInitialSetOfCoins(numCoins=11)
index, count = procedure(coins)
print(f"Original random array: {coins} \nThe lightest coin is located at index {index} and was found after {count} weighings.")
Results
We are dividing and conquering our problem size into chunks of 3 for each iteration of our procedure. Given that these chunks are somewhat equal, this suggests some
Given you have
trials on a two pan balance at your disposal. What is the maximum number of coins that you would be able to start with for the trials?
Going in reverse, each trial triples the number of coins, this means we have the following relationship
which we can solve for
Only values of
You can convince yourself that this pattern will always apply. As long as
Visualize it
Running the algorithm on a varying set of initial coins yields the following results
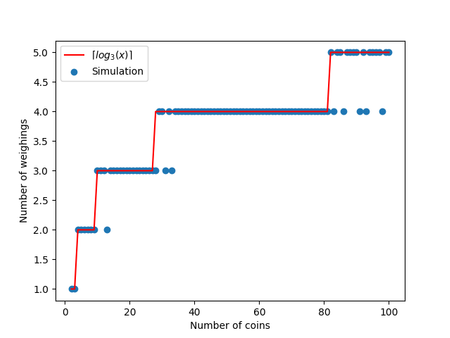
The red line is the worst-case maximum number of trials we'd have to make in order to determine the counterfeit coin. The blue dots are the number of trials the algorithm actually made to determine the fake coin.
Note that there are times where the algorithm performs better than the worst-case maximum. For five initial coins for example, we divide our coins into groups of two, two and one. If the counterfeit coin happens to be in a stack with two coins in it, we'd need to make an additional weighing. We might however luck out and find the counterfeit coin to be in the last group of only one coin, therefore skipping the need to do one last weighing. This happens more often for number of coins that are larger than, but closer to numbers that are powers of three. Now that I come to think about it, perhaps the choice of strategy for dividing the coins could impact this average trials needed. Perhaps dividing the coins into two groups with the same number of coins and leaving the last one larger will yield better average-case results?
Footnotes