Subtractive problem solving
In this blog post, I want to write about something very dear to me. To start off, I'll introduce you to a study that has been written about countless times on the internet. So much, perhaps, that I fear it might have reached the realm of "morning news science" - when a scientific paper or study, propelled by sensationalism, turns into a headline that either misses the intended point completely or is based on poorly conceived science to begin with.
The LEGO tower
The article, titled People systematically overlook subtractive changes, was published in Nature in 2021 and it describes a series of experiments and studies performed with a sample of around 1,500 participants in total. These studies and experiments all have in common that they test people's ability to consider subtractive transformations to solve problems. How exactly are the authors defining subtractive changes?
The cognitive science of problem-solving describes iterative processes of imagining and evaluating actions and outcomes to determine whether they would produce an improved state. The essential elements of these processes are mental models of the original state, of possible transformations, and of action categories that can produce the transformations. We conceptualize subtraction and addition as action categories that remove components from or add components to the original, respectively. When a transformed state has fewer components than the original (for example, a revision with fewer words or a process with fewer obstacles), we describe it as a subtractive transformation; when a transformed state has more components than the original, we describe it as an additive transformation.
In summary, subtractive changes are those we apply to solve problems that leave the result lessened in some way. However, it's not always easy to determine what kind of changes should be considered subtractive or additive, as many changes tend to reduce in some areas and add to others simultaneously. Sometimes, changes can neither be defined as subtractive nor additive at all.
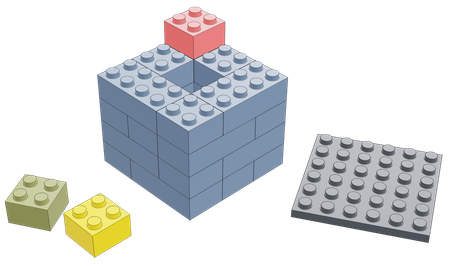
In one of the experiments conducted by the researchers, participants were presented with a LEGO tower consisting of a rectangular foundation and a tile piece supposed to represent a roof to be placed on top. In one of the four corners of the foundation, a single 2x2 block was placed, making the roof unstable when placed on top of the foundation. Additionally, the participants were given a set of LEGO pieces to use during the experiment.
Their task was to make changes to the foundation so that placing the tile-piece on top of the revised structure would make it stable. The participants were also given $1 for participating, and told that any pieces they add to the solution would cost them $0.1 each.
![[missing alt]](https://cdn.sanity.io/images/t0kmv9vc/production/69b7824b797b7543698ab21fdb3f39b4f7b00962-785x861.png?w=450)
![[missing alt]](https://images.ctfassets.net/etyu8fms5usu/1lWsfvSVayagq2EIuQGRh9/22814eda075894c9b6c5b8d03a1644c6/lego-sol-2.png)
The two categories of solving this task are shown in the figures above. Participants could either remove the one problematic piece (subtractive solution) or add enough pieces to the existing structure to make it stable (additive solution).
Results
The control group for the experiment consisted of participants who were not explicitly reminded that removing pieces was allowed. While both groups were told they could modify the structure as they pleased, the control group was told something along the lines of "each piece that you add costs ten cents." In contrast, the subtraction-cue group was told that "each piece that you add costs ten cents, but removing pieces is free." When participants were not explicitly reminded about the subtractive solution, around 40% of them solved the puzzle in a subtractive manner. When participants were reminded about being able to remove LEGO pieces at no cost, around 60% of them resorted to the subtractive solution. The same patterns emerged in the other experiments and studies that were conducted as well. People tend towards additive solutions, especially under higher cognitive load. These results felt very familiar to me, and I recognize this type of problem-solving not just from playing with LEGOs, but also in everyday problems I and others face, be it in the household, in relationships, or even in code. Let's dig deeper into the latter.
Subtractive code
I got curious to investigate whether I'd be able to quantify and spot this phenomenon in human-written code. It certainly feels like I come across fixes like this way too often:
// Before
function formatName(person) {
return `${person.firstName} ${person.lastName}`
}
// After
function formatName(person) {
if (!person) return;
return `${person.firstName} ${person.lastName}`
}
But cherry-picked anecdotes aside, spotting these kinds of additive fixes isn't always so easy. Before jumping into some experiments ourselves, I thought I'd first share some thoughts on why I think this type of problem-solving often appears in our codebases. Perhaps some also carry over to domains outside of code as well.
First of all, the path of identifying the cause of the problem often corners us into a small context in which we apply our problem-solving magic. For example, an error trace on the Before-code above might lead us to identify that the failure mode was a type error trying to access fields on undefined, which is the failure mechanism. The context of this discovery is rather small, and unless we explicitly challenge ourselves to question the context itself, it's easy to fall into the trap of an additive solution because we give ourselves very little room to work in.
Another reason why I think we tend towards this type of problem-solving is what I would perhaps too easily shrug off as laziness, but there are certainly elements of pragmatism that justify it as well. In order to solve this problem on a higher level (i.e., outside this method, rather than inside), we'd have to spend more time trying to understand where and how this method fits into the bigger picture. When is it called, and why is it called in this manner (person being undefined)? What structural changes could we apply to our codebase in a way that renders this failure mechanism obsolete? These questions can be hard to answer without spending significant time, and some might find that the solution requiring less mental work is the best in terms of energy, time, and money spent, even though the resulting code is more complex.
Lastly, I'd also like to point out that I often see conformance to the established context as one of the reasons developers justify these kinds of fixes. To address this issue in a sound manner means, at least to some degree, challenging the status quo and modifying parts of the system that others might have already established. In the LEGO tower experiment, this could manifest as participants justifying additive changes by thinking that the corner piece has been set up by the researchers and is therefore not to be touched. This is actually similar in tone to what some people have answered after being questioned about why they chose not to intervene as subjects in practical experiments of the trolley problem (see: Vsauce - The Trolley Problem in Real Life). It requires a certain kind of rebel to not consider this a problem, but I find that reminding myself or others of the following to be almost equally effective in combating it:
- The codebase as a whole is often not made by a single person with a grand unified vision. It is the accumulation of atomic contributions made by different people at different points in time.
- Even if the system WAS designed by a single person with this grand unified vision, they certainly can't predict the future. In evolving software products, our assumptions, understandings, and desires change over time. It is very likely that the failure mode is a consequence of ever-changing software that was not meant to do what it is supposed to do today.
In the real world
In order to analyze codebases for additive vs. subtractive problem-solving, we need to define logical strategies that answer these two questions:
- What defines "problem-solving" in code?
- What defines an additive or subtractive solution?
Defining a problem
In my team, we started out by ensuring all our squashed commits into the main branch adhere to semantic commit messages. Besides letting us integrate some pretty cool CI/CD workflows using Google's release-please GitHub action, it properly tags each commit into main with a type that makes static code analysis like we are about to do much easier. A "problem-solving" could then easily be identified as a commit with a fix type. We could potentially include other commit types as well, but it's important that we are able to separate code that adds new functionality (which is very often expected to "add" something to the system) from code that fixes a problem in existing code. The refactor-type commits are also candidates for selecting problem-solving commits, but fix and feat-type commits are the only user-facing types of commits that aim at modifying code that affects end-users of the software product.
What is a subtractive problem solve?
Our second prerequisite task to analyzing code for subtractive changes is defining what exactly is meant by subtractive and additive problem-solving. It is commonly accepted that code has a tendency to degrade over time, and there are tons of metrics out there that aim at quantifying complexity, like Cyclomatic complexity. However, I preach in the church of LOC, a metric that simply relates code complexity with the number of lines of code in the source code. This has proven to be a viable metric that is also very simple to calculate. A subtractive solution to problematic code is, in this regime, simply a commit that removes more code than it adds. This information is available on a commit basis, so it should be rather simple to extract as well.
The analysis
We have defined a strategy for both expressing what a problem-solving piece of code change is, and what constitutes a subtractive change. Now it's time to actually analyze some code. I created a Python program that comes with its own little CLI. This program essentially lets you input a git repository, either by providing it with a clonable link or a path to the repository on your own machine, and it will scan through every single commit and summarize with some information around the number of subtractive changes in the code.
I wanted to modularize the strategies for selecting and counting commits as described in the previous two sub-sections, so I implemented the strategy pattern to allow anyone to contribute with their own strategies. For example, the code for selecting which commits are problem-solving commits described above looks like this:
class SemanticCommitSelectorStrategy(CommitSelectorStrategy):
@staticmethod
def select_commits(commits):
filtered_commits = []
for commit in commits:
if re.search(
r"^(fix){1}(\([\w\-\.]+\))?(!)?: ([\w ])+([\s\S]*)",
commit.message,
re.IGNORECASE,
):
filtered_commits.append(commit)
return filtered_commits
There's a similar implementation for counting the number of commits that count as commits containing subtractive changes. Using this system, you could, for example, define a subtractive solution as letting an LLM choose commits that indicate a problem-solve and use cyclomatic complexity as a method for calculating subtractive changes just by plugging in your own strategies.
I browsed around on GitHub looking for repositories that are rather large, rely on semantic commit messages, and have a somewhat rich commit history. Running the script on these 7 repos in total gave these results:
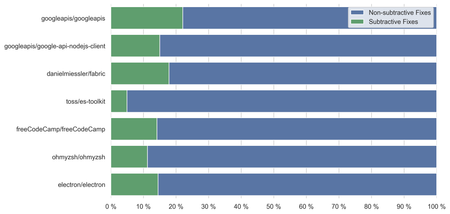
I won't read too much into these results in this post, but my initial reaction to seeing these numbers is that the number of subtractive problem-solving commits was surprisingly low